
How to Choose the Right Database for Your App
Making those database decisions a little easier and a little wiser
Working on new projects is always super exciting — we have the freedom to design and architect the things any way we want. But this planning, when not done properly, can cause us a lot of pain in the future.
Choosing your app database is one of the critical decisions you’ll have to make, and with this article, I intend to introduce you to various database options — along with listing some pros and cons to help you make wiser database decisions.
Key–Value
Our database is structured just like a JSON object — every key is unique, and each key points to some value.
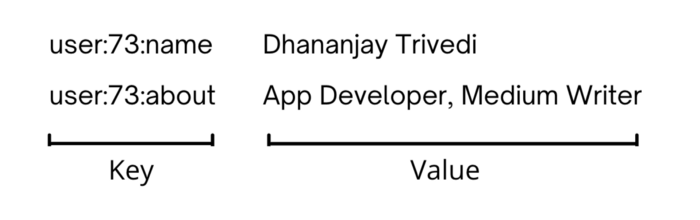
It keeps the data in the memory, which is very fast but comes with a capacity limit, so you can’t store a huge amount of data. And since there’s no disk involved, everything is blazing fast.
There are no queries or joins involved, so there isn’t much data modelling to worry about. Since there’s no schema, the developers always have the flexibility to change data as they may like.

When to use this technique
- This technique is mostly used as a caching mechanism for when some part of the data is being very frequently fetched and observed
- Hence, the key–value technique is widely used along with other databases as a caching mechanism

Wide Column
This is like key–value but on steroids. The value is modified to store a set of columns instead of just plain data.
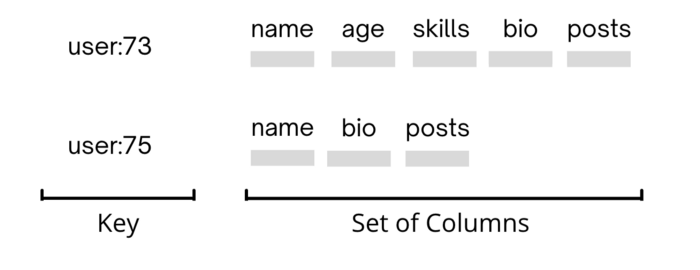
With the introduction of columns, you can now group your related data, but still, there’s no standard schema in place. Hence, each of the keys can point to differently grouped data.
Since there’s no schema, it can handle unstructured data and comes with a query language called CQL, which is similar to SQL but way less powerful. Data comes in a continuous stream, like from an IoT device, stock market, financial transactions, or your Netflix watch history.

When to use this technique
- Frequent writes
- Infrequent updates or reads
This is still not general-purpose. Hence, it can be used for storing historical data from all of our different apps.
Document-Style Database
This is one of the most popular database techniques we use. This obviously consists of documents, and each document is a set of key–value pairs. They’re unstructured and don’t require a schema.
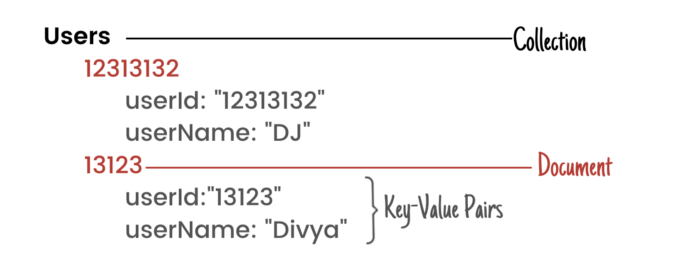
Documents are grouped together into collections, and these collections can be structured into a logical hierarchy.
This logical collection of data lets you group your related data in a much more logical manner, which seems similar to a relational database.

Since our database can’t run join queries, what do we do to get all that related data at once?
We store it all together! We encourage the denormalization of your database and data duplication/inconsistency is a trade-off we’re ready to make.
Reads are really fast, but writing and updating the data while making sure its consistent can be a bit of a challenge.
The document database is a really great fit for general-purpose apps and might be a good fit for most of the apps, games, and IoT.
If you really aren’t sure about your database schema, then a document database is the best way to start.
Popular document-type databases

The document-style database falls short when you have a lot of data, which might be directly or indirectly related to each other.
For those scenarios, you’ll have to run multiple complex queries and then merge all the received data in the front-end application, or you can use a relational database where these complex queries are managed by the database.
Relational Database
We all have heard about these databases, and the most popular ones are MySQL, Postgres, and SQL Server. They’ve been here for a while and still are a popular choice for many applications.
We use Structured Query Language (SQL).
Significance of “relational”
Imagine a car factory where there are different hubs that manufacture the car parts.
Let’s say the doors are manufactured at one place, while the wheels, the body, and the interiors are all made at their own different locations.
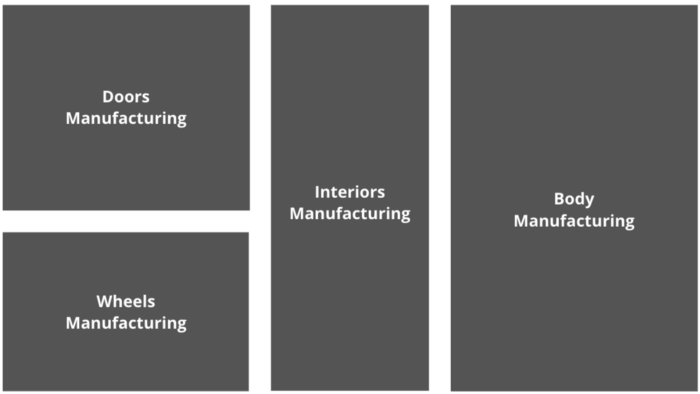
Each manufactured part has a unique ID assigned to it.
So once a car has to be assembled, you can fetch all of the parts from all of these different locations and assemble your car.
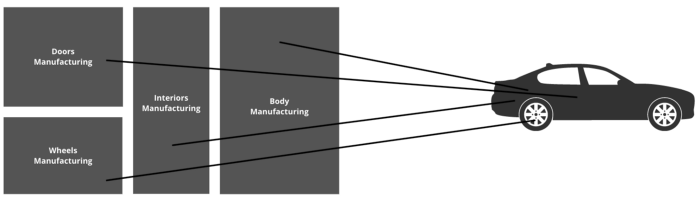
For building such a factory, we’d create the blueprint for such a factory, which makes sure that the overall process of manufacturing the car is very efficient and optimal. This blueprint is called a schema when it’s used in a database.
Hence, we need to plan out the schema for our database to make sure our database is also very efficient for our application’s data needs.
The downside
- Just like how, over time, changing the layout of a car factory to coincide with changing requirements will cost a car company a ton of time and money, it’s a similar situation when a large-scale application has to do so. Make sure to use a relational database when your requirements are clear.
- Also, once you build a plant with the capacity of manufacturing 30 cars a month, you can’t easily scale your plant to make 90 cars a month. Similarly, our relational databases can be harder to scale, but there are some exceptions like Cockroach DB and PostgreSQL that are designed to work at scale.
The good side
- The SQL databases are ACID-compliant, which means our data validity and integrity are never compromised, even though the read-write operation might fail in between — which makes it a great fit for banking/financial-related data
- Once you have a schema in place, you can be assured the data stored will always be stored in a fixed structure following a set of validations, which you’d have defined in the schema.
What’s the best fit for you?
- If your requirements are clear and you’re sure that you won’t be needing any drastic changes to the requirements, go for this one
- If you’re not so sure about the requirements and are in sort of an experimental phase, it’s better to go with a NoSQL database
But what if we don’t need to create a schema and can directly store the relationship as data?
Graph Database
Here our data is stored in the nodes, and the relationship is defined as edges. It’s pretty sweet! Let’s see how.
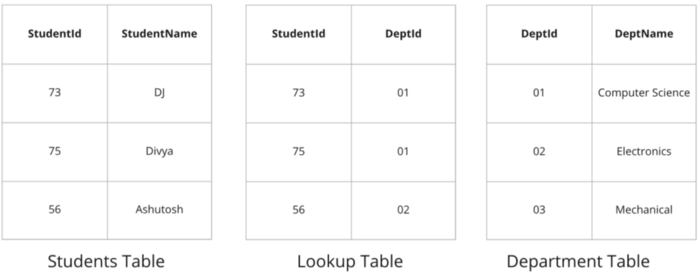
If you have to find out all of the students studying computer science in a SQL database, you’ll need a lookup/middleman table that stores records of all the students studying computer science separately.
In graphs, it’d just be way more straightforward, as we won’t have to store the relationship part of our data separately, and it comes instinctually with this new style.
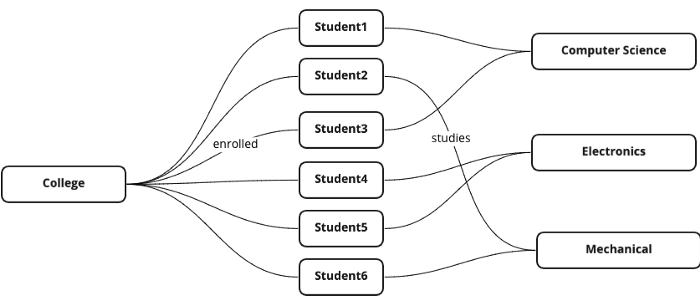
With this new way of directly showing the relationship between two nodes, our complex join queries here become much more simple, greatly improving the performance of the database when compared to SQL.
Hence, use such a database when you’re dependent on a lot of join operations and the performance is degrading because of that.
Searchable Database
If you’re building an application like Google, where on a small-string query search you have to return all of the matching records fast — you’re talking about a full-text search engine.
These databases are based on the Apache Lucene project started in 1999.
Algolia and MeiliSearch are full-text search engines.
They look similar to a document-type database. We have an index, and we add data objects to it. The search-database engine will analyze all of the text in the document and create something called inverted indexes.
When you query something, the database only goes and checks in the inverted indexes, which makes the overall process look blazing fast, even for a large database.